LingmeiZhao.github.io
Sentiment Analysis on Hotel Reviews
Sentiment Analysis is critical in text data mining, and I am passionate about it. Therefore, I did an independent project of analyzing about 35,912 hotel reviews, which I downloaded from Kaggle. This data set is perfect for sentiment analysis because it has users’ ratings for hotels, that represent users’ sentiment bias. According to the ratings, I can divide every review in train dataset into positive and negative. In this way, I can quickly solve the problem of a hand-classified dataset. The following is the whole process I did this project.
Data Cleaning
This dataset has a big problem, which is the reviews have different languages. I write a program to detect the reviews written by their languages, then delete them. Therefore, the dataset is clean.
Data Visualization
I plotted a bar chart to analyze the top ten states in the USA with most hotel reviews. Also, I used a words cloud about hotel marks, which can reflect hotels’ types in the dataset. I also plotted a words cloud about reviews to analyze the frequency of words in the hotel review. These graphs are posted as follows.
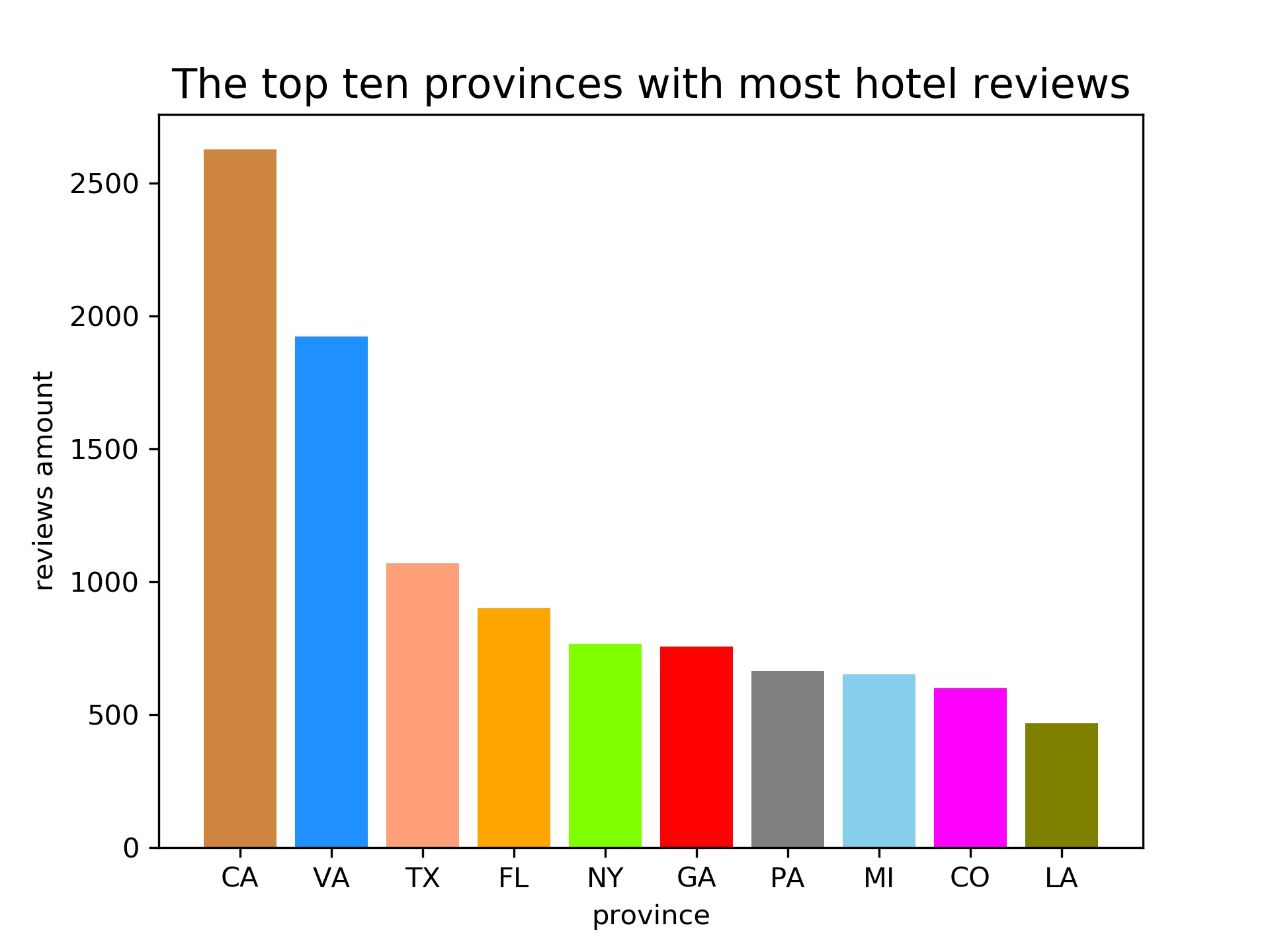


Data Modeling
Feture Selection
I needed to select important words as features to train my model. Therefore, I used the Chi-square test to pick essential words. Meanwhile, I calculated the frequency of every phrase. The elements should have significant chi-square value and high rate. Based on this rule, I select about 1000 words as features.
Model Construction
Using the selected feature to match the reviews. If a review has the word, then the corresponding feature is marked as 1, otherwise 0. Therefore, a matrix is constructed by these way. Next, I trained my model using Logistic Regression. Finally, using the training result to get the test result, and compare with the real results.
Model Result
I used confuse matrix to analyze the model result. The program code is as follows.
import pandas as pd
import nltk
from nltk.corpus import stopwords
pd.options.display.max_columns = 9999
def remove_stop_words(words):
newWords = [ ]
stop_words_set = set(stopwords.words("english"))
for word in words:
if not (word in stop_words_set):
newWords.append(word)
return newWords
def get_all_words(reviews):
all_words = [ ]
for review in reviews:
for word in review:
all_words.append(word)
all_words = set(all_words)
all_words = list(all_words)
all_words = remove_stop_words(all_words)
return all_words
def get_word_dict(all_words):
word_dict = { }
for word in all_words:
word_dict[word] = 0
for review in reviews:
for word in review:
if word in word_dict:
word_dict[word] += 1
return word_dict
def is_word_with_letters(word):
for c in word:
if c.isalpha():
pass
else:
return False
return True
def remove_non_letter_word(word_freq):
words = word_freq["word"].tolist()
filter_column = [ ]
for word in words:
if str(word) == "nan":
filter_column.append(False)
else:
filter_column.append(is_word_with_letters(word))
return word_freq[filter_column]
def select_by_pos(words, tag):
tokens = nltk.pos_tag(words)
selected_words = [ ]
for token in tokens:
(w, t) = token
if t == tag:
selected_words.append(w)
return selected_words
df = pd.read_csv("hotel_reviews3_english.csv")
reviews_text = df["reviews.text"].tolist()
reviews_title = df["reviews.title"].tolist()
reviews = [ ]
for i in range(len(df)):
reviews.append(nltk.word_tokenize(reviews_title[i]) + nltk.word_tokenize(reviews_text[i]))
all_words = get_all_words(reviews)
#selected_words = select_by_pos(all_words, "JJ") + select_by_pos(all_words, "NN")
word_dict = get_word_dict(all_words)
word_dict_keys = list(word_dict.keys())
word_dict_values = [ ]
for key in word_dict_keys:
word_dict_values.append(word_dict[key])
word_freq = pd.DataFrame({"word":word_dict_keys, "freq":word_dict_values})
word_freq = word_freq.sort_values(by = "freq", ascending = False)
word_freq = remove_non_letter_word(word_freq)
word_freq.to_csv("word_freq.csv", index = False)
df.to_csv("hotel_reviews4.csv", index = False)
The confuse matrix graph:
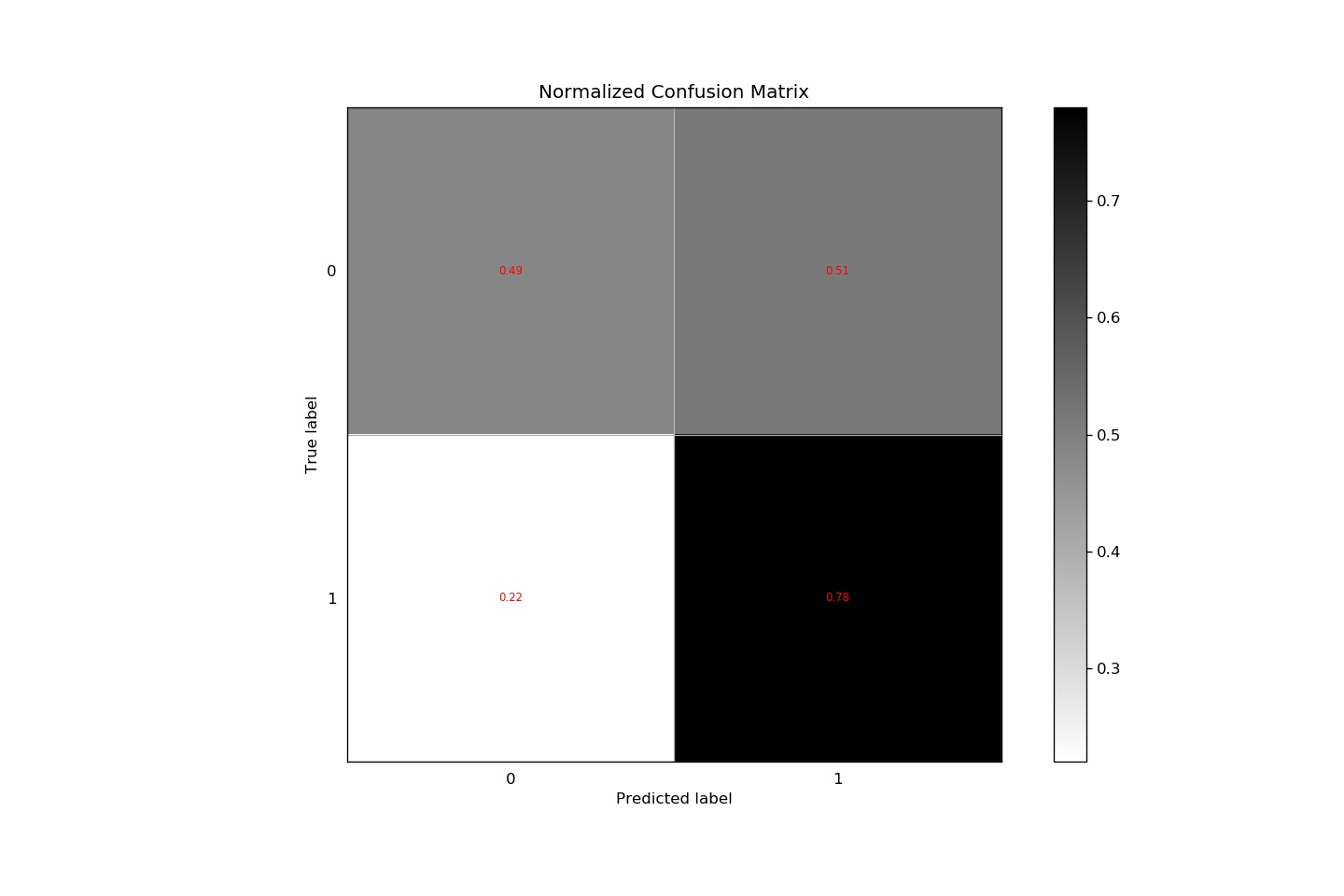 The total precise is about 63%. The model has better performance on positive review.
The total precise is about 63%. The model has better performance on positive review.